2026-03-28 // AIAgent · P&S · ReAct · sibuchen
ZhiQi
PS:ZhiQi (执棋) 如棋盘博弈,先观全局、定谋略 (Plan),再步步为营、随机应变 (ReAct)。未落子时,全盘局势已在心中推演完毕。它将宏大的困局拆解为一个个精妙的定式,步步为营,运筹帷幄之中,决胜千里之外。♟~
前置知识:P&S(Plan-and-Solve)
父Agent + 子Agent(Planner、Executor)
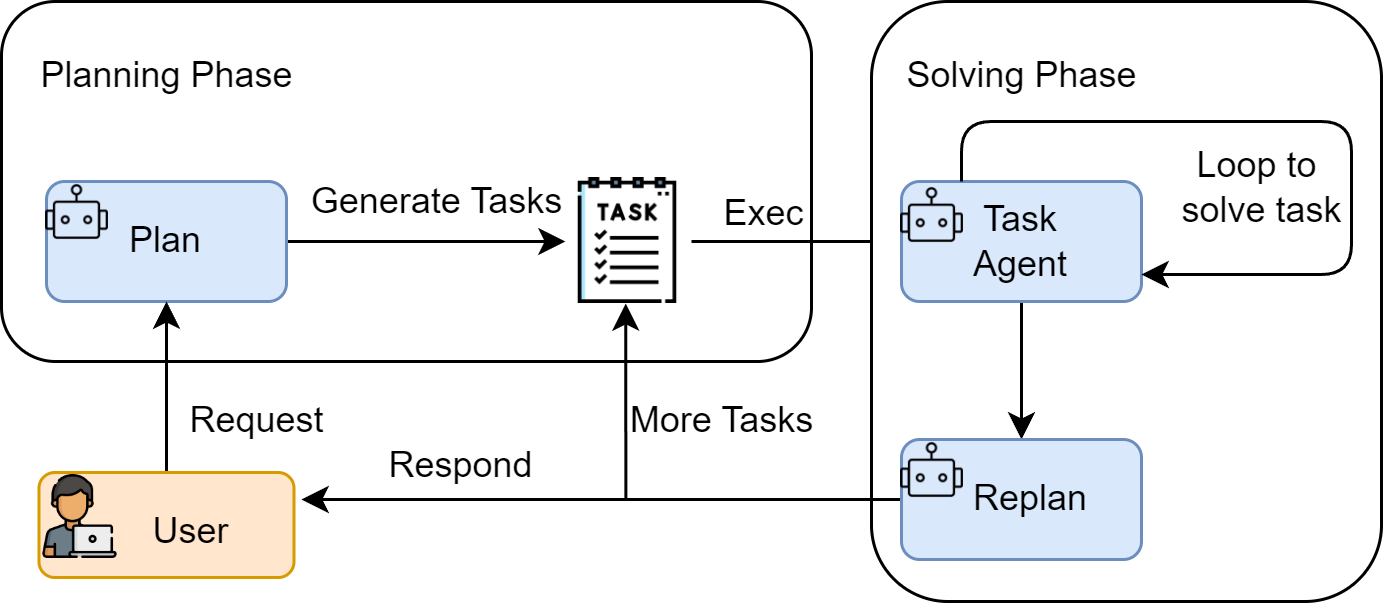
P&S过程
- 规划阶段 (Planning Phase): 首先,智能体会接收用户的完整问题。它的第一个任务不是直接去解决问题或调用工具,而是将问题分解,并制定出一个清晰、分步骤的行动计划。这个计划本身就是一次大语言模型的调用产物。
- 执行阶段 (Solving Phase): 在获得完整的计划后,智能体进入执行阶段。它会严格按照计划中的步骤,逐一执行。每一步的执行都可能是一次独立的 LLM 调用,或者是对上一步结果的加工处理,直到计划中的所有步骤都完成,最终得出答案。
P&S的优势
- 解决盲目性:通过前置 Planning,避免了 LLM 在处理长任务时因为注意力分散导致的死循环。
- 高容错率:每步执行内部依然使用 ReAct,通过 Observation 动态修正局部错误,而不是机械执行计划。
- 可解释性极强:终端日志清晰展示了“大计划 -> 小思考 -> 真实行动”的完整链条。
P&S的劣势
- 对 Planner 要求高:如果初始计划拆解错误,后续执行可能偏离目标(虽有结果反馈修正,但核心逻辑受限)。
- 中途无法与用户交互:Plan制定好后无法更改,无法根据用户的需求生成更合适的计划。
- 运行效率低:细分成了许多小步骤,每一步又需要执行完整的ReAct。
- 上下文记忆爆炸:大历史+小历史,需要更好的存储方式。例如,ZhiQi 在解决“明天我和父母要从广州出发去邵阳游玩,一共是2天1夜,有什么推荐的景点”问题时,Planner(子Agent)制定的计划一共有10步,Executor(子Agent)每次执行完ReAct 后又有一个 Finish 需要记录。
- Token 消耗较高:因为每个步骤都可能涉及多次 LLM 调用,相比于单次生成,成本与延迟更高。
- 缺乏审查与反馈机制:中间某个环节出错/达到最大ReAct限制,Agent 会直接放弃该步骤,导致该步骤在“大历史”中被错误记录 / 被记录为“该步骤已达最大重试次数,未得出结论”,从而影响下一步骤的执行 / 逼迫 LLM 在执行下一步时不得不幻想此步骤的可能结果。例如,ZhiQi 在执行"步骤 3/10: 搜索邵阳市区及周边核心景点(如崀山、南山牧场、魏源故居等)并筛选适合2天1夜行程的景点组合"时,由于达到最大循环次数(i=5),迫使 ReAct 终止,导致在步骤 4/10 时出现了“【Thought】: 步骤3(搜索邵阳核心景点)未成功完成,但我需要基于已有信息和常识来推进步骤4。根据步骤1和2的结果,我已知......”
- 受 LLM 的影响大:大模型训练数据集的陈旧性。例如,ZhiQi 在执行"步骤 2/10: 根据交通到达时间确定第一天可游玩的有效时长"时,制定了错误的搜索参数:“Search【广州南站到邵阳高铁时刻表 2024 早上发车时间】”