2026-03-25 // AIAgent · ReAct · sibuchen
WenJian
PS:“问”代表推理与探询,“剑”代表行动与决断。WenJian (问剑) 如侠客行走江湖,每遇迷障,先凝神“问”道于心(Reason),随即挥“剑”破局(Action)。剑出必有回响(Observation),回响再引剑招,往复之间,迷雾散尽 🗡~
前置知识:ReAct(Reasoning and Acting)
推理使得行动更具有目的性,而行动则为推理提供了事实依据。
ReAct过程
- Thought(思考):内心独白。分析当前情况 分解任务 制定下一步计划 / 反思上一步结果。执行Search函数 传入参数"sibuchen"
- Action(行动):具体动作。调用外部工具 / 输出。Search("sibuchen")
- Observation(观察):环境变化。从外部工具返回的结果。"计科学生"
- 循环 上下文增加 直到Action=输出
ReAct 范式中的“思考-行动-观察”协同循环图解:
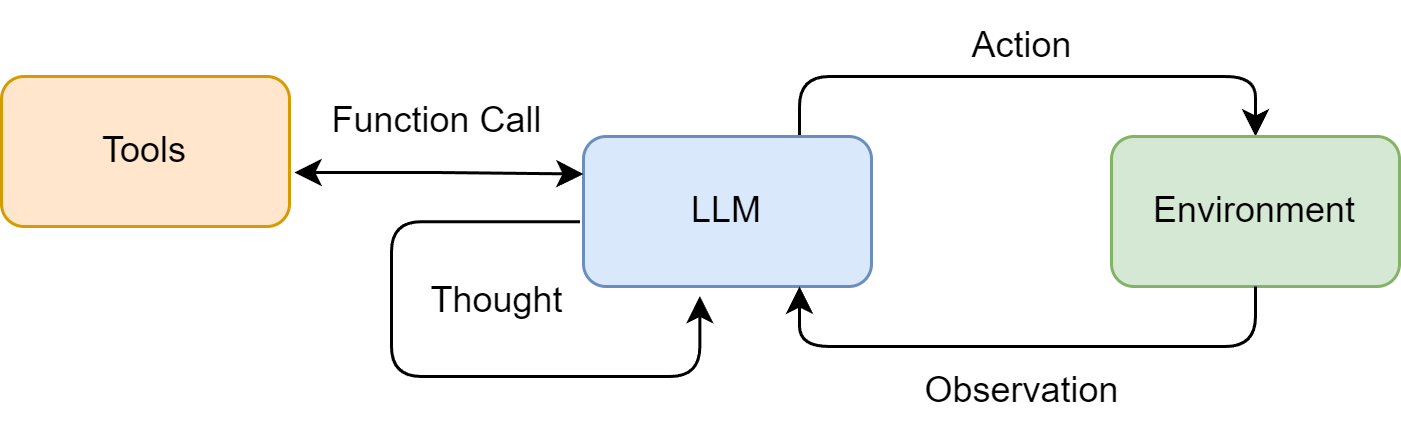
ReAct场景
需要调用外部工具API的场景:查询实时信息、搜索专业知识、使用专业工具(计算器、代码解释器)、操作数据库、调用第三方服务API
tools的三要素
- 名称:一个简洁、唯一的标识符,供智能体在Action中调用
- 描述:一段清晰的自然语言描述,说明这个工具的用途。最为关键。LLM依赖此描述来判断何时调用此工具
- 执行逻辑:真正执行的函数/方法
WenJian VS Nova
🛠️ 核心差异 (Differences)
| 模块 | WenJian 进阶实现 |
|---|---|
config/settings.py | 1. 完善的 配置检查 验证机制 |
llm/client.py | 1. 自动读取 setting 配置文件 (无需手动传参) 2. 严密的 超时控制 3. 强制熔断 机制 (严防模型幻觉) 4. 流式响应 及其异常保护处理 |
agent 核心逻辑 | 1. 动态工具箱 (Prompt 实时注入) 2. 单样本 (One-shot) 引导逻辑 3. 工具执行器 (Executor) 统一管理 4. 工厂模式 (Factory) 实现配置与逻辑深度解耦 5. 支持运行时 动态注册/修改 工具 6. 规范的 LLM 输出解析器 7. 提示词模板拆分 (System + User 分离响应) 8. 三重熔断 安全架构 (Prompt + Client + Core) 9. 极其清晰的 ReAct 状态机与记忆 链路 |
🤝 共同基因 (Similarities)
- ✅ 核心范式: 均遵循标准 ReAct 推理闭环逻辑
- ✅ 容错能力: 内置标准循环计数 (容错机制 i=5)
- ✅ 输出净化: 自动截断多余的冗余 Thought-Action 对
- ✅ 记忆溯源: 完整支持多轮历史对话上下文记忆
ReAct的优势
- 思考(易产生幻觉)+ 行动(易缺乏规划)= 相互影响
- 形成”Thought + Action + Observation“链条 -- Agent所有行为公开透明 -- 高可解释性 -- 有助于 理解、信任、调试 Agent
- 动态规划与纠错 -- 没用一次性生成完整计划 而是 ” 走一步,看一步 “ 每一步的 Observation 都会影响下一步的 Thought 和 Action ,可以实现Agent自我调优。例如,在 WenJian 查询 ” 张雪峰怎么了?“ 时,它认为 Observation 的结果可能是谣言 于是再执行了相同的 Action 并细化了搜索参数。
- Agent = LLM + Tools + History + Core -- 实现了LLM(亚符号)与外部Tools(符号)的深度结合 有效避免了LLM幻觉(例如 计算 解析 搜索任务)
ReAct的劣势
- 过度依赖LLM ,LLM的逻辑推理能力直接影响 Thought 的有效/正确规划,LLM的指令遵循能力与格式化输出能力直接影响 Action 的有效性。这就是为什么 WenJian 要在 core 中实现对各自可能错误的”驳回“。甚至 Agent 的效果会受到 LLM 训练时的数据集影响,例如 WenJian 在搜索 ”张雪峰怎么了?“ 时,LLM 出现了 ”2026是未来时间,该消息是谣言“ 的误判。-- 尝试不同的模型/参数
- 执行效率低下,每次 Thought 只规划一步(Action),每次得到 Observation 才进行下一次 Thought 。一个任务需要多次执行串行的ReAct循环,需要多次调用 LLM ,需要消耗大量的时间。
- 提示词的脆弱性,整个机制建立在一个精选设计的提示词模板上,模板中任何一个微小的变化,设置是用词的差异,都会影响 LLM 的行为。例如,在prompt中去掉对Observation的描述("你当前正处于一个 Thought -> Action -> Observation 的闭环决策链中") 可以大幅度降低幻觉。另外,由于 Thought 中心化堆积在一个 LLM 中,导致在处理复杂的任务时提示词容易失效,LLM 出现越权行为。例如 WenJian 在处理 ” 邵阳有哪些好玩的地方?“时本意是想先搜索邵阳的热门景点,再搜索各个景点的具体介绍与推荐,但是由于上下文的堆砌,导致 LLM 直接幻想出了 Observation 的内容,并自我迭代”Thought + Action + Observation“链条。-- 为promot添加少样本
- 不适合需要规划的长期任务,步进式决策模式使得 Agent 缺乏一个全局的、长远的规划,容易造成绕远路/原地打转的循环当中。例如 WenJian 在处理 ”张雪峰怎么了?“ 时,出现时间的误判后就执着于搜索 ” 张雪峰社交媒体账号头像的颜色 “ 在无关的搜索中陷入了死循环。-- 打印完整 ReAct 流程进行分析